
Build and Automate a Serverless ETL Pipeline with AWS Lambda [2/2]
In Part 1, I created a Python script to collect data from Youtube trending videos and save it to AWS RDS MySQL instance. However, that script was running in my laptop, it’s time to make it serverless!
I’m going to automate the ETL Pipeline in AWS Lambda and schedule to run it daily. The code can be found in my github.
Amazon provides well-documented tutorial, besides, there are many videos, for instance, How to perform ETL with AWS lambda using Python that can show the process in a quick and clear way. Basically, here are the steps:
Create Lambda function
lambda_function.py
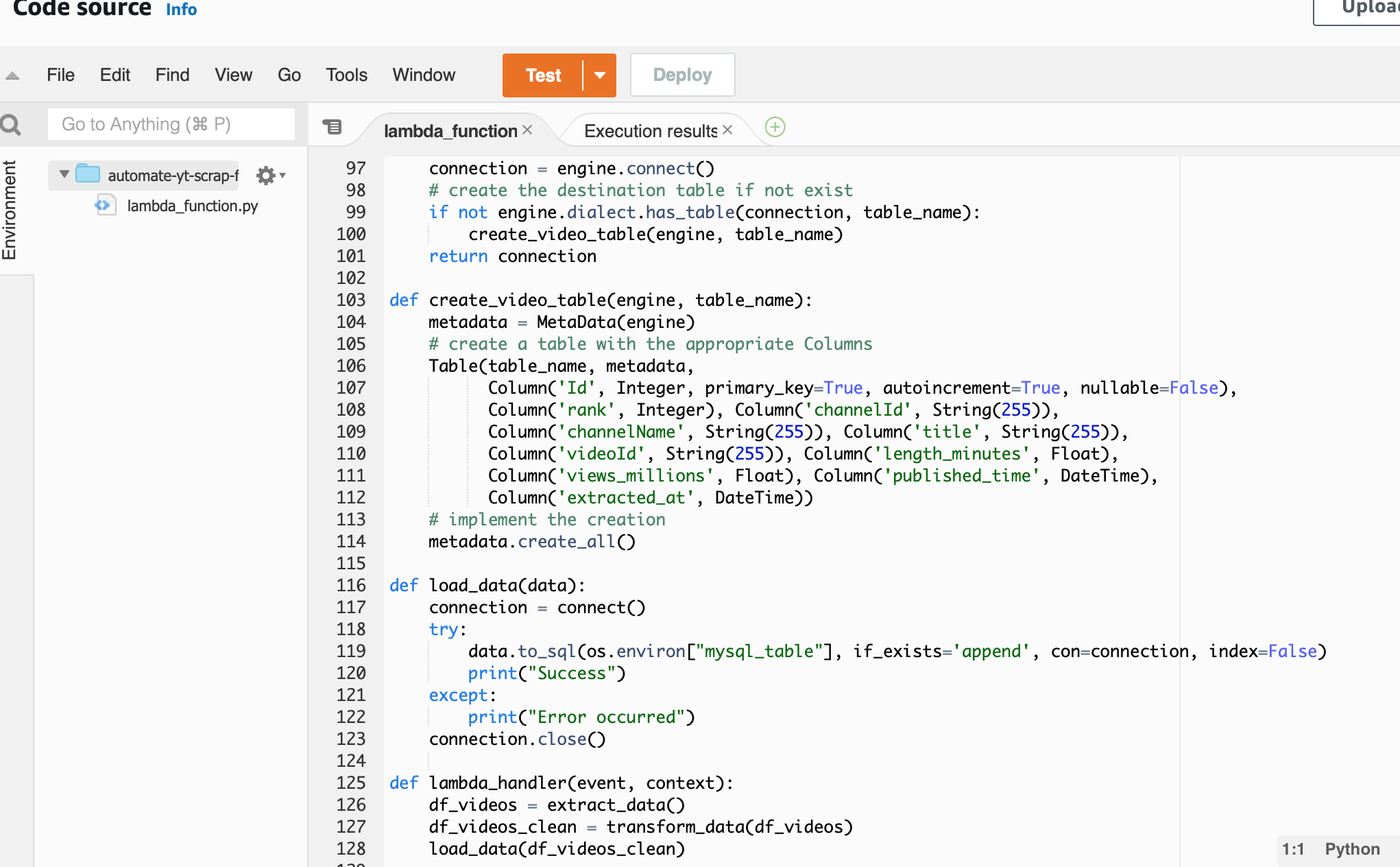
Add Layers
The script requries 5 Python packages: Pandas, Numpy, Requests, SQLAlchemy, and PyMySQL. There are 3 ways to add a layer, I think it’s convenient to specifiy a layer by providing the ARN. For instance, specify an ARN for Pandas:
Test
Click “Test” button to execute the code, check “Execution results”.
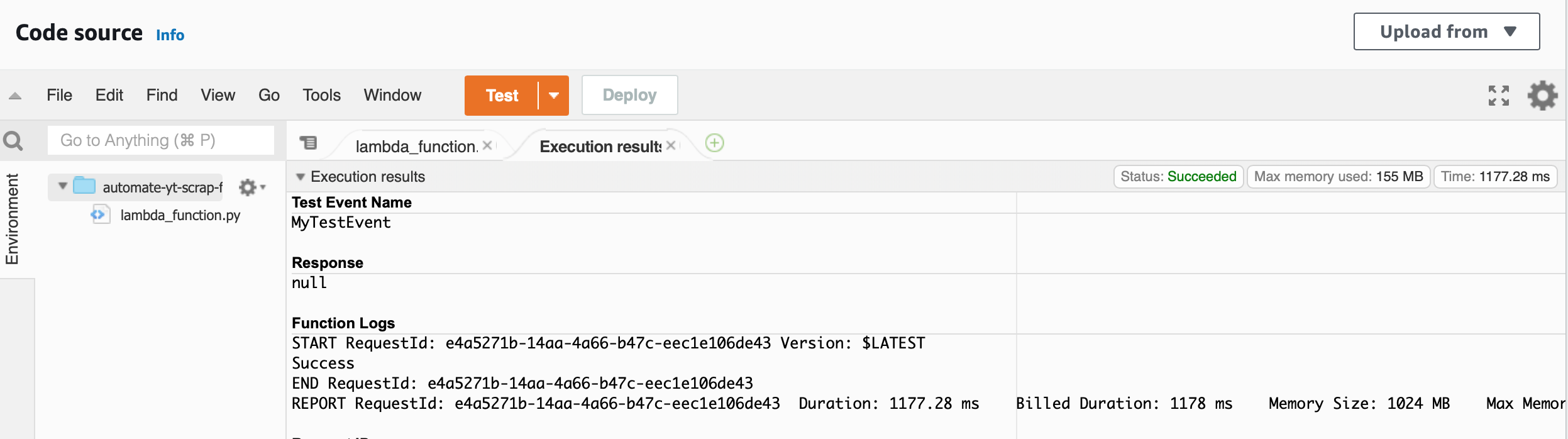 There is no errors.
There is no errors.
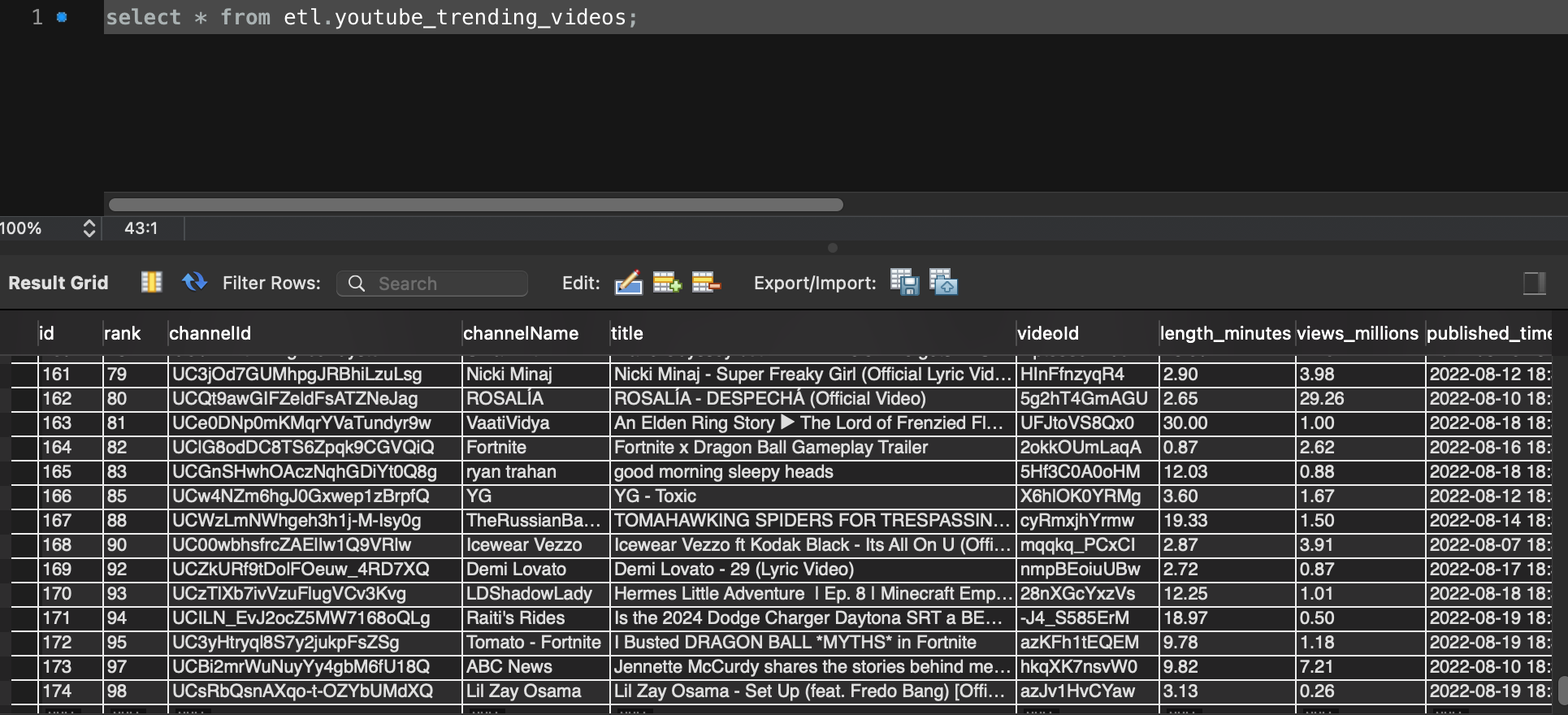
Double check MySQL, table youtube_trending_videos did update.
Automate AWS Lambda function using Amazon EventBridge CloudWatch
Event schedule
Follow this tutorial to create a rule in Amazon EventBridge. Set the cron expression to 0 18 * * ? *, it will run at 18:00 UTC (11:00 AM PST).
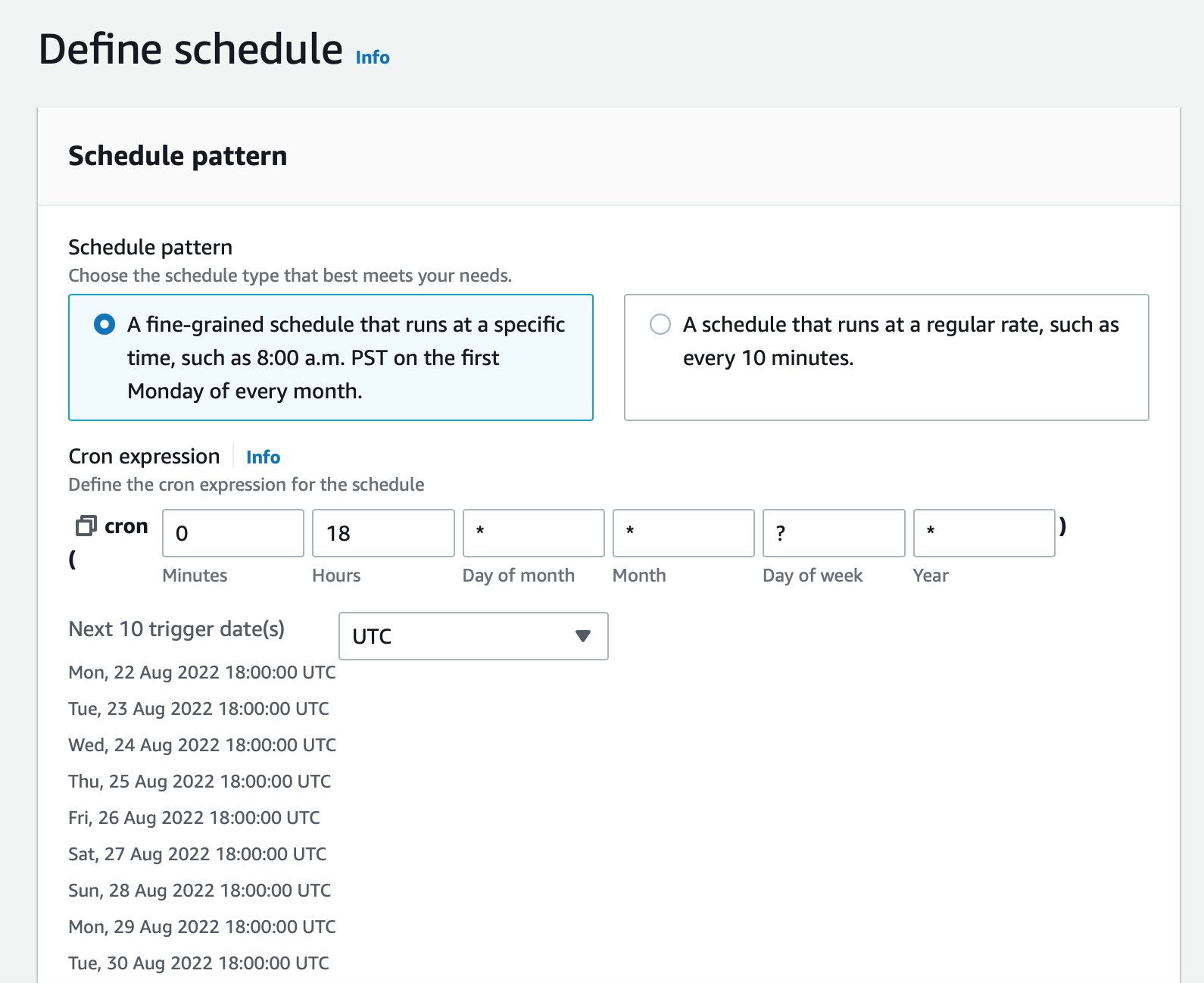
Targets
Set the Lambda function I created earlier as the target.
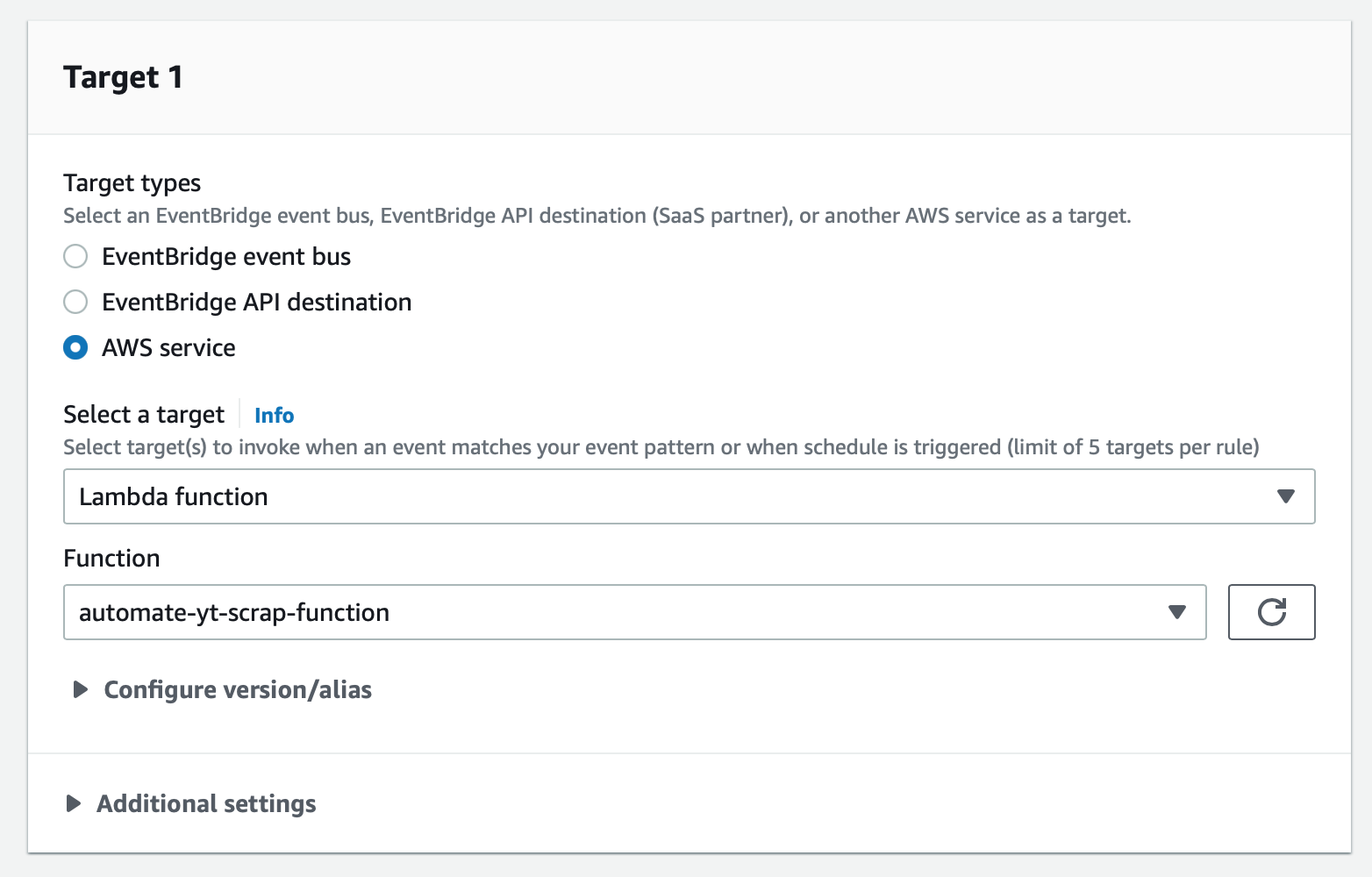
Summary
In Part 1 & Part 2, I have implemented the following concepts:
- Creation of AWS RDS MySQL instance.
- Creation & configuration of AWS Lambda function.
- Automation of AWS Lambda function with Amazon EventBridge.
With this ETL pipeline, I just need to wait for enough data of Youtube trending videos for future analysis.