
Build and Automate a Serverless ETL Pipeline with AWS Lambda [1/2]
Introduction
The term ETL pipeline refers to the processes of extraction (from the cloud/APIs/databases/files), transforming (the raw data), and loading of data into a database such as a data warehouse.
I’m going to create an ETL pipeline in Python, below is the general idea:
-
Extract — extracting information of Youtube Trending videos from Youtube Search and Download API. Those trending videos updates roughly every 15 minutes. With each update, videos may move up, down, or stay in the same position in the list. In Part 1, I will pull the data once and focus on how to create the pipeline. In Part 2, I’m planning to create a scheduled ETL workflow, that is, call the API at regular intervals to get new trending videos.
-
Transform — cleaning and formatting data from the API’s JSON responses to Pandas Dataframes.
-
Load — writing the data into MySQL in AWS RDS.
Extraction
Request from the API
Sign up for Rapid API, go to the Youtube Search and Download API and then hit “Subscribe to test”. It offers multiple pricing plans, select the free “Basic” one:
import pandas as pd
import requests
import importlib
# import API keys, MySQL user/password from api_keys.py
import api_keys
def get_video_info(content):
if "video" in content:
video = content["video"]
# remove thumbnails
video.pop("thumbnails", "No Key Found")
return video
else:
return None
def extract_data():
"""
Type of trending videos:
n - now (default)
mu - music
mo - movies
g - gaming
"""
querystring = {"type":"n","hl":"en","gl":"US"}
url = "https://youtube-search-and-download.p.rapidapi.com/trending"
headers = {
"X-RapidAPI-Key": api_keys.rapid_api_key,
"X-RapidAPI-Host": "youtube-search-and-download.p.rapidapi.com"
}
response = requests.request("GET", url, headers=headers, params=querystring)
# convert response string to JSON
response_json = response.json()
contents = response_json['contents']
df = pd.DataFrame([get_video_info(content) for content in contents])
return df
df_videos = extract_data()
df_videos.head()
| channelId | channelName | lengthText | publishedTimeText | title | videoId | viewCountText | |
|---|---|---|---|---|---|---|---|
| 0 | UCOmHUn--16B90oW2L6FRR3A | BLACKPINK | 3:14 | 21 hours ago | BLACKPINK - ‘Pink Venom’ M/V | gQlMMD8auMs | 80,090,195 views |
| 1 | UCCE5NVlm0FhbunMMBT48WAw | Fundy | 15:09 | 11 hours ago | So I Made Minecraft More Satisfying... | 1N22qIy_vHs | 753,860 views |
| 2 | UCJbYdyufHR-cxOuY96KIoqA | AMP | 45:37 | 1 day ago | AMP GOES TO THERAPY | 6M9UG1ueBZU | 943,982 views |
| 3 | UCvj3hNvwrEgTRkeut7_cBAQ | JiDion | 12:15 | 1 day ago | Spending The Day With A Loch Ness Monster Expert! | WRhCmAgEmYs | 1,740,342 views |
| 4 | UCISglu-JC04IuYH13mfYHzw | Dabl | 4:10 | 1 day ago | Undercover Boss Of Checkers Restaurant Is Forc... | h6dL2un7YGg | 944,094 views |
Transformation
First of all, we need to remove missing values and duplicates.
Besides, We need to convert lengthText and publishedTimeText to datetime, and convert viewCountText to numbers.
Neither channel name nor video title is unique, let’s keep channelId and videoId as the identifiers. And we need to record the current ranking in trending.
import re
from datetime import datetime, timedelta
def get_length_minutes(s):
t = 0
for u in s.split(':'):
t = 60 * t + int(u)
# convert total seconds to minutes
return round(t/60, 2)
def get_published_time(s):
unit_list = ["weeks", "days", "hours", "minutes",
"seconds", "milliseconds", "microseconds"]
now = datetime.now()
parsed_s = [s.split()[:2]]
unit = parsed_s[0][1]
if unit in unit_list:
time_dict = dict((fmt,float(amount)) for amount,fmt in parsed_s)
elif unit+"s" in unit_list:
time_dict = dict((fmt+"s",float(amount)) for amount,fmt in parsed_s)
elif unit in ["month", "months"]:
time_dict = dict(("days",float(amount)*30) for amount,fmt in parsed_s)
elif unit in ["year", "years"]:
time_dict = dict(("days",float(amount)*365) for amount,fmt in parsed_s)
else:
return now
dt = datetime.now() - timedelta(**time_dict)
return dt
def get_views_count(s):
count = ''.join(re.findall(r'(\d+)', s))
# get count in millions
count_m = round(float(count)/1E6, 2)
return count_m
def transform_data(data):
# remove duplicates
data.dropna(inplace=True)
# remove rows where at least one element is missing
data.drop_duplicates(inplace=True)
# add column of current ranking
data.index += 1
data = data.rename_axis('rank').reset_index()
# add column of extracted at
data["extracted_at"] = datetime.now()
# convert text to other formats
data["length_minutes"] = data["lengthText"].apply(get_length_minutes)
data["published_time"] = data["publishedTimeText"].apply(get_published_time)
data["views_millions"] = data["viewCountText"].apply(get_views_count)
# remove unneeded columns
data.drop(columns=["lengthText", "publishedTimeText", "viewCountText"], inplace=True)
return data
df_videos_clean = transform_data(df_videos)
Loading
I did the following steps:
- Step 1: sign up for AWS.
- Step 2: follow Tutorial and select “Free Tier” plan to create a MySQL DB instance in AWS RDS.
- Step 3: follow Instruction to connect MySQL Workbench to AWS RDS.
- Step 4: create schema and table
youtube_trending_videosin the AWS RDS DB instance.
Here is the code to load the dataframe into MySQL.
import pandas as pd
from sqlalchemy import create_engine
import pymysql
def connect():
user = api_keys.mysql_user
pwd = api_keys.mysql_pwd
host= api_keys.aws_endpoint
port = api_keys.mysql_port
database= api_keys.mysql_db
engine = create_engine(f"mysql+pymysql://{user}:{pwd}@{host}:{port}/{database}")
connection = engine.connect()
return connection
def load_data(data, table):
connection = connect()
try:
data.to_sql(table, if_exists='append', con=connection, index=False)
print("Success")
except:
print("Found Error")
connection.close()
load_data(df_videos_clean, "youtube_trending_videos")
Success
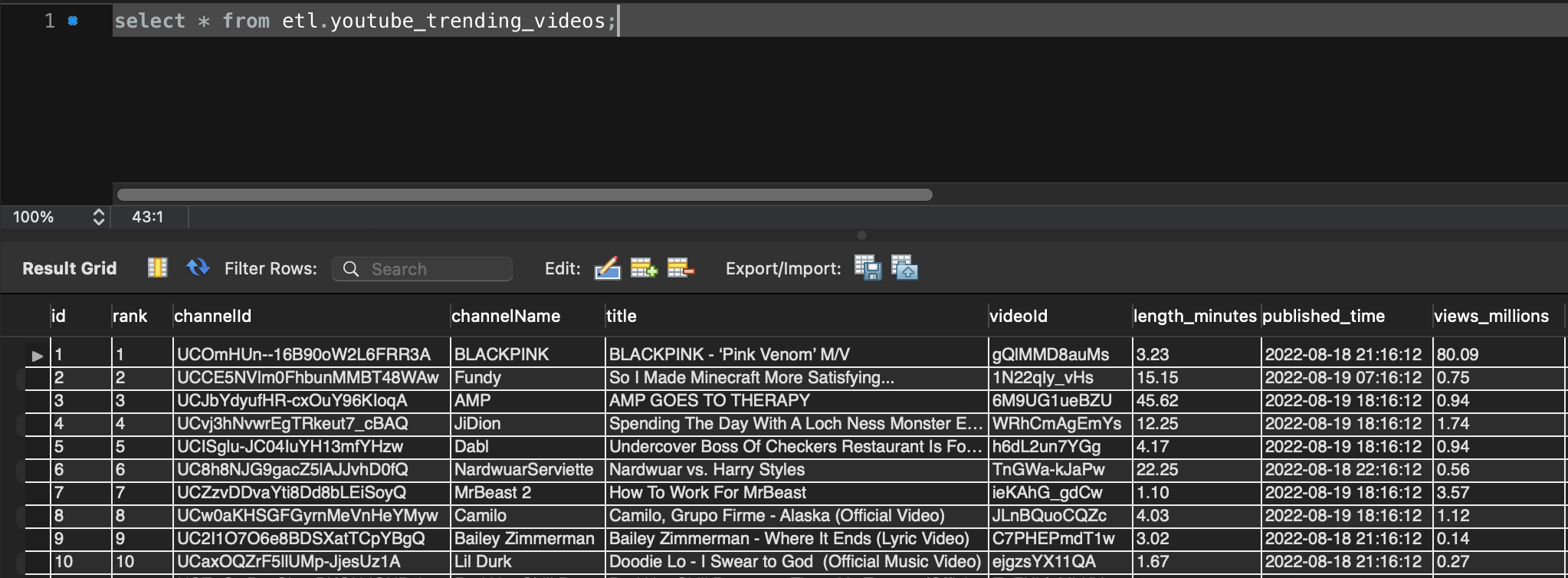
Double check that table in MySQL Workbench, it did saved successfully.
The end
In Part 1, I’ve created a simple ETL pipeline that can extract the data of Youtube trending videos, transform it with Python libraries, and then load it to AWS RDS. But the script is still running in my laptop.
I’m going to use AWS Lambda to make the pipeline severless and run the code daily in Part 2.