
Four R packages for Automated Exploratory Data Analysis
Introduction
Exploratory data analysis (EDA) is a critical step in any data science workflow. Inspired by the article on medium, I’d like to explore the 4 most popular R EDA packages based on their downloads. The dataset is from my project Chicago Bike-Share Analysis, to make it more efficient, I’m going to sample 10% of its original size.
Import the data
library(tidyverse)
# for clean output, quit the message showing the guessed column types
options(readr.show_col_types = FALSE)
set.seed(1)
df <- list.files(path = "Bike-Share-Data",pattern = "*.csv", full.names = TRUE) %>%
lapply(read_csv) %>%
bind_rows
# get load 10% of original dataset
df_sample <- df %>%
sample_n(round(nrow(df)/10,0), replace = FALSE, prob = NULL)
head(df_sample)
| ride_id | rideable_type | started_at | ended_at | start_station_name | start_station_id | end_station_name | end_station_id | start_lat | start_lng | end_lat | end_lng | member_casual |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <dttm> | <dttm> | <chr> | <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <chr> |
| D19CD62061C56CFC | classic_bike | 2021-08-22 16:52:48 | 2021-08-22 17:28:14 | <span style=white-space:pre-wrap>Wood St & Hubbard St </span> | <span style=white-space:pre-wrap>13432 </span> | <span style=white-space:pre-wrap>Wood St & Hubbard St </span> | 13432 | 41.88990 | -87.67147 | 41.88990 | -87.67147 | member |
| EB24C059C9BEE023 | electric_bike | 2021-08-20 22:34:09 | 2021-08-20 23:06:58 | <span style=white-space:pre-wrap>Dearborn St & Erie St </span> | <span style=white-space:pre-wrap>13045 </span> | California Ave & Division St | 13256 | 41.89419 | -87.62946 | 41.90303 | -87.69746 | casual |
| 064A7468D993FE0B | electric_bike | 2022-04-14 07:15:08 | 2022-04-14 07:24:14 | NA | NA | NA | NA | 41.94000 | -87.70000 | 41.95000 | -87.72000 | member |
| 2E3852512AC429F6 | classic_bike | 2021-06-08 18:20:49 | 2021-06-08 18:42:45 | Fort Dearborn Dr & 31st St | TA1307000048 | Field Blvd & South Water St | 15534 | 41.83856 | -87.60822 | 41.88635 | -87.61752 | member |
| ACF8FF1A88DC6FC0 | electric_bike | 2021-10-12 14:36:18 | 2021-10-12 14:44:56 | <span style=white-space:pre-wrap>Wabash Ave & Wacker Pl </span> | TA1307000131 | <span style=white-space:pre-wrap>Canal St & Adams St </span> | 13011 | 41.88686 | -87.62648 | 41.87947 | -87.64021 | casual |
| BE48602F3CF4EE17 | classic_bike | 2021-07-04 12:57:19 | 2021-07-04 13:10:02 | <span style=white-space:pre-wrap>Clark St & Berwyn Ave </span> | KA1504000146 | <span style=white-space:pre-wrap>Broadway & Thorndale Ave </span> | 15575 | 41.97800 | -87.66805 | 41.98974 | -87.66014 | casual |
Rank packages
Putatunda et al. (ref link) shared an insightful comparison between SmartEDA and other similar packages available in CRAN for EDA.
Let’s rank these cited packages based on the downloads in the last 12 months.
library("dlstats")
# rank popular EDA related packages
stats <- cran_stats(c("SmartEDA", "DataExplorer", "tableone", "GGally", "Hmisc",
"exploreR", "dlookr", "desctable", "summarytools"))
stats %>%
filter(start >= "2021-08-01" & end < "2022-08-01") %>%
select(package, downloads) %>%
group_by(package) %>%
summarize(downloads = sum(downloads)) %>%
arrange(desc(downloads))
| package | downloads |
|---|---|
| <fct> | <int> |
| Hmisc | 9741969 |
| GGally | 890258 |
| DataExplorer | 207483 |
| SmartEDA | 197655 |
| summarytools | 178863 |
| tableone | 144601 |
| dlookr | 44637 |
| desctable | 7015 |
| exploreR | 4800 |
I’m going to try the top 4 packages: Hmisc, GGally, DataExplorer, and SmartEDA.
Hmisc
There is no function in Hmisc can create a overall report of the input dataset, we have to call specific functions based on specific needs. describe is one of the popular functions, let’s have a try.
library(Hmisc)
# describe all variables in a data frame
describe(df_sample)
Loading required package: lattice
Loading required package: survival
Loading required package: Formula
Attaching package: ‘Hmisc’
The following objects are masked from ‘package:dplyr’:
src, summarize
The following objects are masked from ‘package:base’:
format.pval, units
df_sample
13 Variables 575755 Observations
--------------------------------------------------------------------------------
ride_id
n missing distinct
575755 0 575755
lowest : 00000B4F1F71F9C2 000022C3D3CE7DD5 000043B681BFB305 0000453517CABB51 00005B17AF7201F6
highest: FFFFA5E4DD5C0668 FFFFB13489EEB3AE FFFFCCFF4A678336 FFFFCD8626C9CC4A FFFFD1346B5EADA0
--------------------------------------------------------------------------------
rideable_type
n missing distinct
575755 0 3
Value classic_bike docked_bike electric_bike
Frequency 319986 29227 226542
Proportion 0.556 0.051 0.393
--------------------------------------------------------------------------------
started_at
n missing distinct Info
575755 0 564875 1
Mean Gmd .05 .10
2021-09-18 19:29:31 9129862 2021-05-20 15:18:44 2021-06-03 10:19:11
.25 .50 .75 .90
2021-07-07 14:56:31 2021-08-31 18:40:37 2021-11-04 06:21:56 2022-03-09 19:17:13
.95
2022-04-09 14:28:10
lowest : 2021-05-01 00:01:07 2021-05-01 00:05:30 2021-05-01 00:10:01 2021-05-01 00:12:46 2021-05-01 00:13:11
highest: 2022-04-30 23:55:08 2022-04-30 23:55:12 2022-04-30 23:57:38 2022-04-30 23:58:03 2022-04-30 23:58:34
--------------------------------------------------------------------------------
ended_at
n missing distinct Info
575755 0 564658 1
Mean Gmd .05 .10
2021-09-18 19:50:28 9129636 2021-05-20 15:41:39 2021-06-03 10:39:22
.25 .50 .75 .90
2021-07-07 15:17:55 2021-08-31 18:58:01 2021-11-04 06:37:02 2022-03-09 19:34:00
.95
2022-04-09 14:42:12
lowest : 2021-05-01 00:11:51 2021-05-01 00:15:29 2021-05-01 00:16:23 2021-05-01 00:18:02 2021-05-01 00:28:49
highest: 2022-05-01 00:14:02 2022-05-01 00:15:21 2022-05-01 00:15:24 2022-05-01 00:16:27 2022-05-01 01:32:41
--------------------------------------------------------------------------------
start_station_name
n missing distinct
497037 78718 855
lowest : 2112 W Peterson Ave 63rd St Beach 900 W Harrison St Aberdeen St & Jackson Blvd Aberdeen St & Monroe St
highest: Woodlawn Ave & 55th St Woodlawn Ave & 75th St Woodlawn Ave & Lake Park Ave Yates Blvd & 75th St Yates Blvd & 93rd St
--------------------------------------------------------------------------------
start_station_id
n missing distinct
497037 78718 847
lowest : 13001 13006 13008 13011 13016
highest: Throop/Hastings Mobile Station Wilton Ave & Diversey Pkwy - Charging WL-008 WL-011 WL-012
--------------------------------------------------------------------------------
end_station_name
n missing distinct
491608 84147 847
lowest : 2112 W Peterson Ave 63rd St Beach 900 W Harrison St Aberdeen St & Jackson Blvd Aberdeen St & Monroe St
highest: Woodlawn Ave & 55th St Woodlawn Ave & 75th St Woodlawn Ave & Lake Park Ave Yates Blvd & 75th St Yates Blvd & 93rd St
--------------------------------------------------------------------------------
end_station_id
n missing distinct
491608 84147 839
lowest : 13001 13006 13008 13011 13016
highest: Throop/Hastings Mobile Station Wilton Ave & Diversey Pkwy - Charging WL-008 WL-011 WL-012
--------------------------------------------------------------------------------
start_lat
n missing distinct Info Mean Gmd .05 .10
575755 0 116555 1 41.9 0.04922 41.80 41.86
.25 .50 .75 .90 .95
41.88 41.90 41.93 41.95 41.97
lowest : 41.64850 41.64850 41.64854 41.64855 41.64857
highest: 42.06478 42.06478 42.06481 42.06485 42.07000
--------------------------------------------------------------------------------
start_lng
n missing distinct Info Mean Gmd .05 .10
575755 0 113875 1 -87.65 0.03164 -87.70 -87.68
.25 .50 .75 .90 .95
-87.66 -87.64 -87.63 -87.62 -87.60
lowest : -87.84000 -87.83000 -87.82931 -87.82000 -87.81000
highest: -87.52838 -87.52836 -87.52823 -87.52823 -87.52000
--------------------------------------------------------------------------------
end_lat
n missing distinct Info Mean Gmd .05 .10
575287 468 94509 1 41.9 0.04935 41.80 41.86
.25 .50 .75 .90 .95
41.88 41.90 41.93 41.95 41.97
lowest : 41.56000 41.57000 41.60000 41.62000 41.64000
highest: 42.06486 42.06497 42.07000 42.08000 42.11000
--------------------------------------------------------------------------------
end_lng
n missing distinct Info Mean Gmd .05 .10
575287 468 92145 1 -87.65 0.03186 -87.70 -87.68
.25 .50 .75 .90 .95
-87.66 -87.64 -87.63 -87.62 -87.60
lowest : -87.86000 -87.84000 -87.83000 -87.82000 -87.81000
highest: -87.52823 -87.52823 -87.52452 -87.52000 -87.50000
--------------------------------------------------------------------------------
member_casual
n missing distinct
575755 0 2
Value casual member
Frequency 254015 321740
Proportion 0.441 0.559
--------------------------------------------------------------------------------
It did provide a quick view of all the variables, but to me, it’s not impressive as the result looks like a combination of multiple functions, such as summary(), str(), and the output format is a little hard to read.
GGally
library(GGally)
options(repr.plot.width = 14, repr.plot.height = 10)
# show the interactions of each variable with each of the others
# distinguish by member_casual
df_sample %>%
select(rideable_type:ended_at, start_lat:end_lng) %>%
ggpairs(mapping = aes(color = df_sample$member_casual, alpha = 0.5))
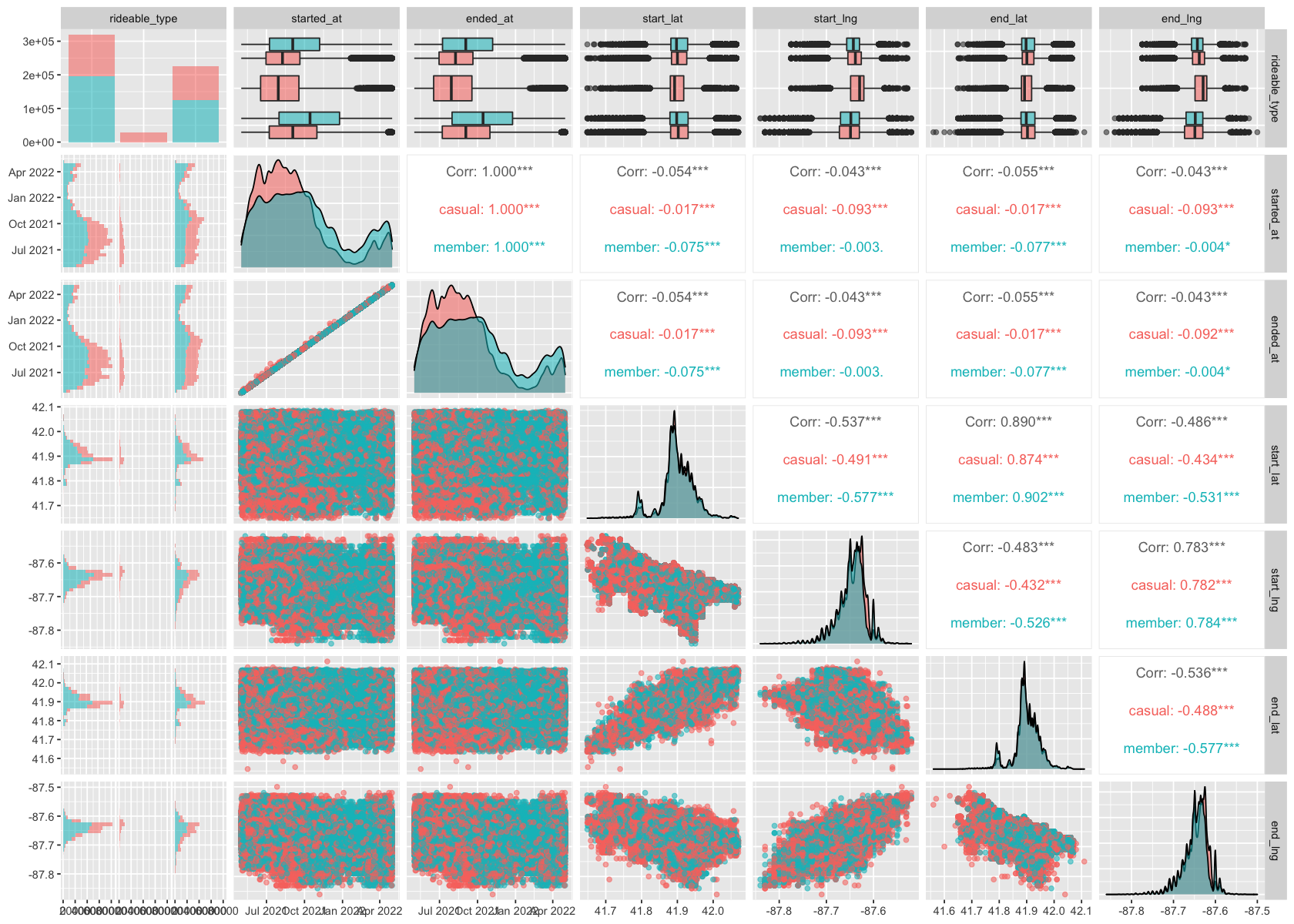
According to the image above, we know different riders (casual and member) have different rideable_type, started_at, and ended_at. That’s a good starting point.
DataExplorer
library(DataExplorer)
data_all %>% create_report(
output_file = paste("Report", format(Sys.time(), "%Y-%m-%d %H:%M:%S %Z"), sep=" - "),
report_title = "EDA Report - Chicago Bike Share"
)
It generated a .html file in the working directory, below is the screenshot:

That report is very informative. I like its Missing Data Profile and Bar Chart.
SmartEDA
library(SmartEDA)
df_sample %>% ExpReport(op_file="SmartEDA_Report.html")
It also generated a .html file and below is the screenshot:

It’s very similar to DataExplorer, but I think its function ExpCatViz() (i.e., 5. Distributions of categorical variables in its report) is better than DataExplorer’s plot_bar() (i.e., Bar Chart (with frequency)), as the former shows percentage instead of frequency.
The end
All of these packages can help us get a general idea of the dataset. Both DataExplorer and SmartEDA can create reports with just one function, that’s super convienent, but none of them is the answer to all questions. We need to combine specific funcitons of above packages to create our own functions for EDA, and then dig deeper.